A Primer on Codis
In the first of this mini-series on Clustering Redis I mentioned Codis as one of the projects doing this for you. In this installment I’m going into more detail on Codis. The authors of the project have made some interesting choices, and these choices make Codis different with different requirements and implications than some of the others.
Basic Introduction
The design of Codis is to have a central closer-structure repository, one or more proxies, and an “HA” component to manage master/slave failover of backend nodes. It provides a Web UI (the “Dashboard”), an HTTP API, and some command-line interface tools which work against the API. Written in Go it has good concurrency support but can be affected by the garbage control aspect of Go.
Quick Highlights
- Performs Well
- Mostly-Transparent Shards
- Slot Migration
- Auto-rebalance
- Operates during migration or rebalance
- Does not require client library changes
- Usable Interface
Overall in my early tests it performs well - easily pulling hundreds of thousands of operations per second split over a pair of nodes and relatively high client concurrency - and this without the client using pipelining. The caveat here is that while the commands are quickly handled, the GC in Go is a pause-the-world type (currently) so you can get a millisecond or two of “GC latency” on a command. In the context of Redis this order of magnitude may sound tremendous. However, if you have active rehashing enabled in Redis you can see this effect sometimes when talking directly to Redis.
The ability to easily migrate slots is a very welcome feature. Combined with the ability to add “server groups” (I’ll get into the details shortly) and then have it automatically rebalance your cluster based on memory usage it makes it a top contender in my book. Anyone using Twemproxy with more than, say a dozen nodes, understand the pain that becomes. For Codis this happens without restarting the proxy process itself - so you don’t lose connections. During this time you can still use your endpoint as you normally do.
In testing so far I’ve seen the aforementioned 100K+ ops/second be maintained during a rebalance operation which was adding 5 new groups. Because it speaks native Redis you don’t need a custom client library. You merely have to not use commands Codis doesn’t support.
The Dashboard could certainly use some UX love, but it is serviceable. The slots page shows you a color-coded table of slots and which group they are assigned to.
Setup
As a Go program you will need to build it just as you do other Go projects. Fortunately this process is easy and a Makefile and “bootstrap” shell script is provided which simplifies some of it even further. The Readme and the Tutorial will get you most of this, so I won’t repeat it here. We need to get into better details and things I’ve discovered about Codis.
The Basic Architecture
Codis is designed to store cluster data in a backing store (defaulting to Zookeeper with Etcd in the works), run a dashboard to handle management, and a proxy to interface clients to the backend. It does, however, require the modified Redis 2.8.13 (as of this writing) to operate against.
Here is the diagram currently in the repo describing the architecture: 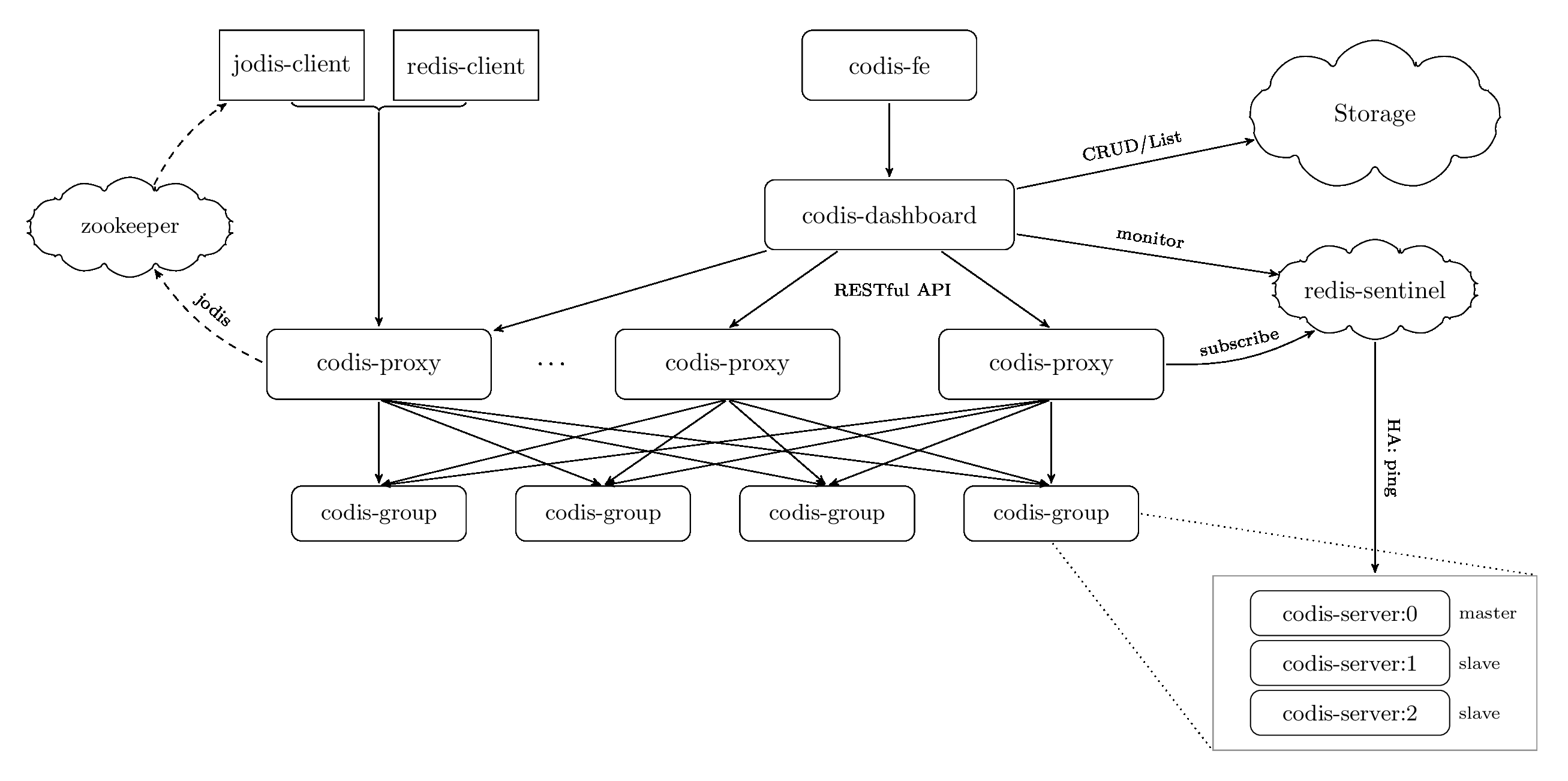
Server Group
The fundamental unit in Codis is the “Server Group”, referenced as “Redis Group” in the diagram but really they are “Codis-Servers” - the modified Redis source to enable slot migration at the server level. This represents one master and, hopefully, one slave. Here we find the first limitation: You can have only one master and one slave in a group. Codes uses the Codis-HA project to provide “HA”.
Except it isn’t HA. All the project does is detect if the server is responding and if not will promote the slave. It requires a single slave, and does zero additional checking to ensure the slave is actually viable. Further, it is a single process which decides this. Even if you have multiple process (ie. multiple dashboards) running a single process can flip the replication without consulting the other nodes. This is, in my opinion, a huge gap and failing. It is too easy for a single process to get a network blip and clause an unnecessary failover.
This reliance on codis-ha should be altered to be optional with the option to call Sentinel available. This would allow you to use Sentinel to provide multi-node validation of a master being unavailable before failing over. Further the system does not do any real checking of the configuration. Currently you can give it a “master” which is actually configured as a slave and Codis will happily accept it. If you then try to rebalance you’ll find yourself in a problematic situation as Codis marks the slots as “migrating” then attempts to migrate them.
In testing I found that this scenario meant you have slots “stuck” - the are offline, in migration status, and no error messages which tell you the node it is migrating them to is actually a slave. For more details you can see the Issue 173. Suffice it to say this is not a situation you want. If Codis allowed you to use Sentinel (which means either proxying the failover command to Sentinel from the “promote” button in the UI or dropping it if configured to use Sentinel) and validated the new backend before migrating slots this problem goes away.
I’m not sure about the Sentinel support (I’ve not added an issue for it yet), but the comment on Issue #173 is that the checking will be implemented.
Now back to what a Server Group is.
A Server group is assigned a bank of slots. Currently the default, hard-coded, non-configurable slot count is 1024. Codis will divide these slots among the server groups. If you have three masters, each in their own group, each slot will have 1024/3 slots in it. I’m not sure what it does with uneven divisions.
Dashboard
This is where the meat of Codis lies. Dashboard is the component which defines and rearranges what servers are in which groups, what slots go to what groups, the status of the cluster and nodes, as well as other bits of metadata. All of this data is stored in Zookeeper. Etc support is in there but the docs and the support are not complete yet.
The web interface the dashboard provides is sufficient and functional, but has plenty of room for improvement.

{kind=link}
The large amounts of white space means you will be doing a lot of scrolling as you grow. In my opinion this needs to be broken out into a more “regular” dashboard interface where you can select which component you’re interested in. For example a tab or view for the performance metrics would be one, viewing and managing server groups another, and status perhaps the default view. This would uncluttered the interface greatly and make it much better and more usable.
There are also a few views linked but not implemented -specifically a “server group” view.
The slots view is interesting but clunky. Clicking on a slot adds slot information at the top of the page. If you aren’t looking at the top you won’t know the link did anything. This also makes it annoying to have to click, scroll up, then back down. This seems a good use for a pop-over. I’d also like to see the table be smaller and perhaps more responsive to the size of the viewport. I don’t like having to scroll right and left to see everything.
A key piece missing from the slots information is the usage of the slots. How many keys are in the slot? How much memory is the slot consuming? These are important bits of information operations wants to have direct access to. Especially once hot-slots begin surfacing.
Perhaps counter-intuitively Dashboard is a command option to the codis-config binary. Another issue I have with it, and it’s a mistake I’ve made before, is it looks for an “assets” directory to live with the codis-config binary. This should be configurable. Alternatively it could be included with use of go-bindata and you’d have the single-binary for deployment.
However, another mistake it makes it expecting the config file to always be in the directory where you execute the command from, or provided on the command line. For example, if you’re in your home directory and the codis-config command is in /usr/local/sbin it will default to looking for config.ini in your home directory.
I’d like to see the default location be in /etc/codis/codis.ini. Even better I’d love for the project to take the next step and make all of the config directives environment variables as you would in Factor 3 of a 12 Factor App (TFA). With all of it’s information being stored in an external backing service this would make a great improvement.
If the project used go-bindata to include the assets and used factor three for config it could be a very easy deploy - and each launch of the codis-config command can have all the information needed in it’s environment meaning no local file access needed.
The dashboard also provides an HTTP API, but I’v not yet done a lot with it, so that will have to wait for an update. Lets move on to the Proxy piece.
Codis-Proxy
The Codis proxy id the component the client library and cod interfaces with. It consults either the dashboard API or the backing service (not sure which) and maps slots to backends. You don’t have to run this with the codis-servers, and indeed I’d probably recommend against it. Sure, you have lower overhead between proxy and backend, but if you lose the host, container, or VM, as the codis-server you’ll lose the proxy. In order to handle this you need either a TCP load balancer or round robin DNS with clients re-executing the DNS lookup and reconnecting - and hoping that one is alive.
The TFA config changes I recommend for codis-config apply perhaps more strongly here. By moving the config to the environment you can have a codis-proxy in a tiny Docker image or be able to run multiple instances without config management. Frankly making the run-time config (via options and env) only point to the configuration backing service (ie. zookeeper, etc., consul, etc.) you can make this really simple. And simple is awesome here.
The implementation of the proxies one that reads and understands the commands it gets from clients - it isn’t fully transparent. It will refuse a bank of commands such as SUNIONSTORE, CONFIG, AUTH, SCAN, KEYS< and FLUSHDB among many others.
I call out those last several because this identifies a gap in the current state of Codis. You have no way for a normal client to iterate over known keys, nor do you have a way to empty your Redis store.
The FLUSHALL command could be implemented by iterating over each group and
doing the FLUSHALL. The FLUSHDB command of course has no use under this type
of setup. I would suggest, however, that adding FLUSHSLOT and FLUSHGROUP
would be quite useful. Sometimes you might need to just empty a slot or a
group. The group flush seems relatively straightforward, but I’m unsure on the
ease of flushing of a slot.
For scanning keys, the same technique could be used - divvy up however many
keys the user requests among the backends, perhaps weighting by key count, run
SCAN, combine and reply. While I nearly always recommend against running
KEYS, the implementation should be pretty straightforward - potentially
better than normal.
For implementing the KEYS command Codis (and this applies to any proxy based
clustering solution) could iterate through successive SCANs on the backends,
collate and reply. That would beat running KEYS but would be more complex to
implement.
Ultimately the problem of not being able to inspect your data store will need to be resolved in COois for it to be, IMO, a viable option.
Tricky Bits
Codis will respond to the info command. But it will essentially pick a backend and give you that data. This is not likely that useful for you unless you repeat the command until you get the data for all the nodes. Then you’ll have to combine it.
This will be tricky, to say the least, for tools which monitor Redis. At this point you can’t rely on such sections as memory or commandstats. What I would like to see here is for Codis to aggregate the commandstats and memory usage sections from all of the master nodes, and to possibly output new fields in the memory section (or even commandstats) which provide the information by server group. That would be stellar, indeed.
More Areas For Improvement
I’ve not been shy about commenting on what I think can be improved so far, but some of the opportunities I see Codis as having don’t fit neatly into the above categories. The main thing I’d love to see is integration of LedisDB support, maybe even Ardb. The author of XCodis could be quite helpful in showing an alternative to modifying Redis (I’ll be writing about that one soon as well). I’ve found that proxy projects which require modification of the servers they proxy fall behind in terms of supporting the original server’s capabilities.
I’d also like to see Consul integration as an option in addition to Etcd and Zookeeper. The service check and DNS capabilities in Consul could be very useful for a Codis cluster, or multiples. The more configuration it can put behind a backing service as opposed to a file, the more flexible and powerful the cluster can become. It would also make for easier integration with dependent systems such as client configuration and TCP load balancers.
PUBSUB is something else I’d like to see implemented. With the proxy having a
backing service available, client subscriptions could be stored in the service
to support reconnects on back end failures - something stock Redis doesn’t have
(though Cluster allows PUBSUB across all nodes) Go’s concurrency support should
make this a nice feature to implement. Alternatively Codis could send PUBLISH
commands to all backends and let SUBSCRIBE commands go to any back end.
Another item which is critical IMO is implementing AUTH. This can be as simple as pulling the auth token from the config (either backing service, config file, environment variable, or command-line option). That said there is an opportunity to do more here. But at a minimum the clients should be able to AUTH to the proxy. Because it is a proxy, the backend Redis instances should be able to (and likely should) have a different auth token.
A final suggestion for improvement (for now) is to cut the time it takes to initialize and “fill” slots. From a brief foray into the code it doesn’t look like something you couldn’t do concurrently. As it is when you fire up the process it takes quite a while to iterate over 1024 slots. Make the slot number configurable, and make the initialization process parallel and this becomes a much more tolerable process.
Overall I quite like Codis, and I’ll likely be cloning and working on some of these things. The project so far seems open to ideas, which will hopefully carry over into it being more than an isolated solution and into something we in the community could really enjoy having.